
آمار و یادگیری ماشین در کنار هم ابزاری قدرتمند برای بهبود پیشبینیها ارائه میدهند. آمار با تحلیل دادهها، شناسایی الگوها و مدیریت عدم قطعیت، پایهای قوی برای مدلسازی فراهم میکند.
از سوی دیگر، یادگیری ماشین با استفاده از توانایی پردازش دادههای بزرگ و شناسایی روابط پیچیده، پیشبینیهایی دقیقتر ارائه میدهد. این ترکیب در حوزههایی مانند تحلیل بازار، پیشبینی رفتار مشتریان و شناسایی تقلب، نتایج بسیار موفقی داشته است.
هوش مصنوعی در آمار با ادغام این دو حوزه، ابزارهایی هوشمندتر و کارآمدتر برای حل مسائل دادهمحور ایجاد میکند.
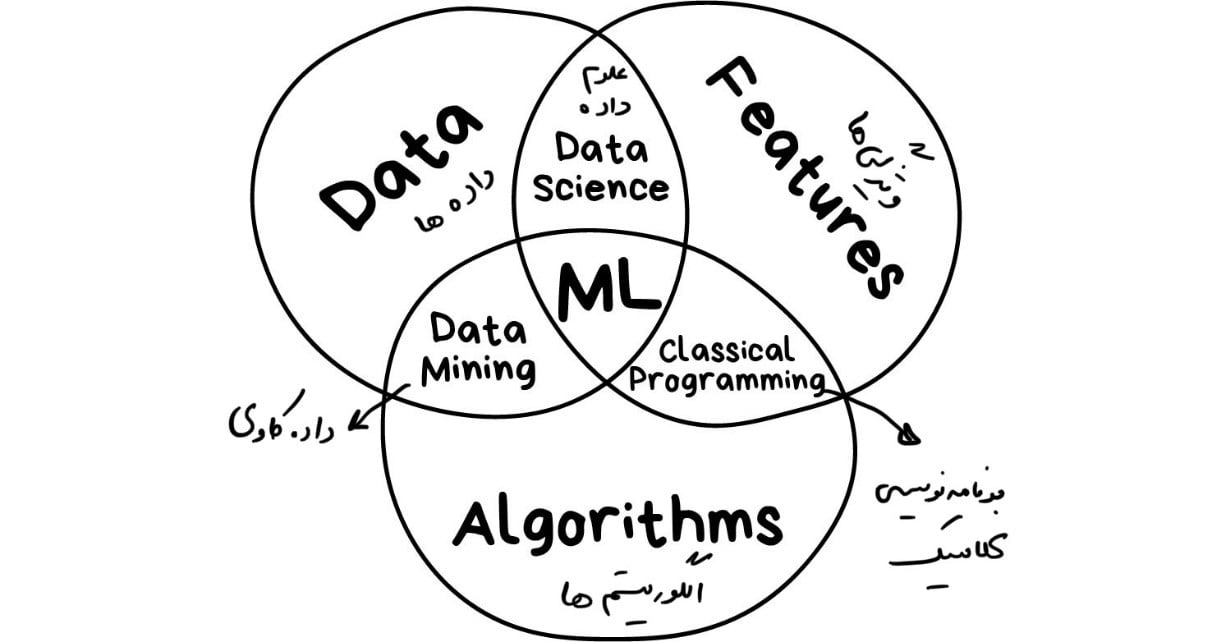
چگونه ترکیب آمار و یادگیری ماشین دقت پیشبینی را افزایش میدهد؟
ترکیب آمار و یادگیری ماشین یک رویکرد جامع برای تحلیل دادهها و بهبود دقت پیشبینیها ارائه میدهد. آمار با تحلیل دقیق دادهها، شناسایی الگوها و مدیریت عدم قطعیت، یک زیرساخت قوی برای یادگیری ماشین فراهم میکند. از سوی دیگر، یادگیری ماشین با قدرت پردازش دادههای بزرگ و شناسایی روابط پیچیده، پیشبینیهای دقیقتر و تصمیمگیریهای هوشمندتر را ممکن میسازد. این همکاری در حوزههایی مانند پیشبینی رفتار مشتریان، مدیریت منابع و تحلیل بازارهای مالی نتایج فوقالعادهای داشته است. در ادامه، نحوه ترکیب این دو حوزه و تأثیر آن بر افزایش دقت پیشبینیها، همراه با مثالهای کاربردی توضیح داده میشود.
1. تحلیل و پیشپردازش دادهها با استفاده از آمار
آمار ابزارهایی برای شناسایی دادههای پرت، ناهماهنگیها و توزیعهای نامناسب ارائه میدهد. این تحلیلها به پیشپردازش دادهها کمک میکند تا ورودیهای بهتری به مدلهای یادگیری ماشین ارائه شود.
مثال:
در پیشبینی فروش یک فروشگاه:
- دادههای تراکنشها نشان میدهد که میانگین فروش روزانه 2,000 واحد است، اما در یک روز خاص 20,000 واحد ثبت شده است.
- تحلیل آماری این مقدار را بهعنوان یک داده پرت شناسایی میکند و با حذف یا تعدیل آن، مدل یادگیری ماشین به دادههای دقیقتری دسترسی پیدا میکند.
نتیجه:
- دقت پیشبینی قبل از پیشپردازش: 85 درصد
- دقت پیشبینی پس از پیشپردازش: 92 درصد
2. مدیریت دادههای نامتوازن با ابزارهای آماری
یکی از چالشهای رایج در یادگیری ماشین، وجود دادههای نامتوازن است. آمار با نمونهبرداری مجدد یا وزندهی به کلاسهای کمتر، به یادگیری بهتر مدل کمک میکند.
مثال:
در تشخیص تقلب در یک بانک:
- از 10,000 تراکنش، تنها 100 مورد تقلبی هستند.
- تحلیل آماری با افزایش وزن دادههای تقلبی یا نمونهبرداری مجدد، تعادل بین کلاسها ایجاد میکند.
نتیجه:
- دقت مدل قبل از مدیریت نامتوازنی دادهها: 75 درصد
- دقت مدل پس از مدیریت نامتوازنی دادهها: 90 درصد
3. شناسایی ویژگیهای کلیدی با تحلیل آماری
آمار به شناسایی ویژگیهایی کمک میکند که بیشترین تأثیر را بر پیشبینیها دارند. این کار باعث میشود مدلهای یادگیری ماشین سادهتر و سریعتر اجرا شوند.
مثال:
در پیشبینی قیمت خانه:
- دادهها شامل متغیرهایی مانند متراژ، تعداد اتاقها، سال ساخت و موقعیت مکانی هستند.
- تحلیل همبستگی نشان میدهد که متراژ و موقعیت مکانی بیشترین تأثیر را بر قیمت دارند، در حالی که سال ساخت تأثیر کمی دارد.
مدل یادگیری ماشین با تمرکز بر این ویژگیهای کلیدی، دقت بالاتری ارائه میدهد:
- دقت مدل قبل از انتخاب ویژگیها: 80 درصد
- دقت مدل پس از انتخاب ویژگیها: 88 درصد
4. شناسایی روابط پیچیده با یادگیری ماشین
پس از تحلیل اولیه دادهها با آمار، یادگیری ماشین میتواند روابط پیچیده و غیرخطی بین متغیرها را شناسایی کند.
مثال:
در پیشبینی رفتار مشتریان یک فروشگاه:
- تحلیل آماری نشان میدهد که تعداد خرید و میانگین مبلغ خرید تأثیرگذار هستند.
- یادگیری ماشین نشان میدهد که ترکیب این دو متغیر (مثلاً تعداد خرید بالا و مبلغ کم) میتواند رفتارهای خاصی مانند خریدهای مکرر اما با مبلغ کم را شناسایی کند.
5. مدیریت عدم قطعیت در پیشبینیها
آمار میتواند عدم قطعیت در پیشبینیها را تحلیل کرده و نتایج مدلهای یادگیری ماشین را قابل اعتمادتر کند.
مثال:
در پیشبینی تقاضای انرژی:
- مدل یادگیری ماشین پیشبینی میکند که مصرف روزانه 1,000 مگاوات است.
- تحلیل آماری نشان میدهد که با 95 درصد اطمینان، مصرف واقعی بین 950 تا 1,050 مگاوات خواهد بود.
این تحلیل به تصمیمگیرندگان کمک میکند تا برای شرایط نامطمئن آماده باشند.
6. ترکیب نتایج آماری و یادگیری ماشین
در برخی موارد، ترکیب خروجیهای آماری و مدلهای یادگیری ماشین میتواند به پیشبینیهای دقیقتر منجر شود.
مثال:
در تحلیل بازار سهام:
- تحلیل آماری نشان میدهد که روند کلی قیمت سهام صعودی است.
- یادگیری ماشین پیشبینی میکند که افزایش قیمت در روزهای خاصی از هفته شدیدتر خواهد بود.
- ترکیب این نتایج پیشبینی دقیقتری از نوسانات بازار ارائه میدهد.
7. بهینهسازی پارامترهای مدل با تحلیل آماری
آمار میتواند در تنظیم پارامترهای مدلهای یادگیری ماشین، مانند نرخ یادگیری یا تعداد لایههای شبکه عصبی، کمک کند.
مثال:
در پیشبینی رفتار کاربران یک وبسایت:
- تحلیل آماری نشان میدهد که کاهش نرخ یادگیری مدل از 0.1 به 0.01 باعث بهبود نتایج میشود.
نتیجه:
- کاهش خطای مدل از 15 درصد به 8 درصد
مدیریت عدم قطعیت در یادگیری ماشین با استفاده از ابزارهای آماری
در یادگیری ماشین، عدم قطعیت به معنای نبود اطمینان کامل در پیشبینیها یا تصمیمگیریها است که میتواند ناشی از دادههای نویزی، کمبود داده یا مدلهای ناقص باشد. ابزارهای آماری نقش حیاتی در مدیریت این عدم قطعیت دارند. این ابزارها به تحلیل دادهها، ارزیابی سطح اطمینان پیشبینیها و ارائه خروجیهای قابل اعتماد کمک میکنند. در ادامه، کاربرد ابزارهای آماری در مدیریت عدم قطعیت همراه با مثالهای عملی بررسی میشود.
1. تحلیل توزیع احتمالات برای پیشبینی دقیقتر
تحلیل توزیعهای آماری به مدلهای یادگیری ماشین کمک میکند تا احتمال وقوع پیشبینیهای مختلف را ارزیابی کنند. این تحلیل به تصمیمگیرندگان اجازه میدهد تا بر اساس سطح اطمینان پیشبینیها عمل کنند.
مثال:
در پیشبینی قیمت سهام:
- مدل یادگیری ماشین پیشبینی میکند که قیمت سهام در روز آینده 1000 تومان خواهد بود.
- تحلیل آماری نشان میدهد که با احتمال 80 درصد، قیمت بین 950 تا 1050 تومان قرار خواهد گرفت.
این اطلاعات به سرمایهگذاران کمک میکند تا ریسکهای خود را بهتر مدیریت کنند.
2. استفاده از فاصله اطمینان برای ارزیابی پیشبینیها
فاصله اطمینان یک ابزار آماری است که بازهای را مشخص میکند که پیشبینیهای مدل با احتمال مشخصی در آن قرار میگیرند. این ابزار به شناسایی میزان عدم قطعیت در پیشبینی کمک میکند.
مثال:
در پیشبینی میزان فروش:
- مدل پیشبینی میکند که فروش روزانه یک فروشگاه 2000 واحد خواهد بود.
- فاصله اطمینان 95 درصد: بین 1800 تا 2200 واحد.
این فاصله به مدیران کمک میکند تا برای تأمین موجودی با اطمینان بیشتری تصمیمگیری کنند.
3. تحلیل دادههای نویزی با ابزارهای آماری
دادههای نویزی یکی از منابع اصلی عدم قطعیت در یادگیری ماشین هستند. ابزارهای آماری با شناسایی و حذف نویز، دادههای تمیزتری برای مدل فراهم میکنند.
مثال:
در تحلیل رفتار کاربران یک وبسایت:
- میانگین مدت زمان حضور کاربران در سایت 5 دقیقه است.
- یک داده با مقدار 50 دقیقه ثبت شده که بهعنوان نویز شناسایی میشود.
با حذف این مقدار، مدل پیشبینی دقیقتری ارائه میدهد:
- خطای پیشبینی قبل از حذف نویز: 15 درصد
- خطای پیشبینی پس از حذف نویز: 8 درصد
4. استفاده از تحلیل سریهای زمانی برای مدیریت عدم قطعیت در دادههای پویا
سریهای زمانی ابزار قدرتمندی برای شناسایی الگوهای تکراری و پیشبینی رفتارهای آینده هستند. این تحلیل به مدیریت عدم قطعیت در دادههایی که با زمان تغییر میکنند کمک میکند.
مثال:
در پیشبینی ترافیک شهری:
- دادهها نشان میدهند که در ساعات اوج، ترافیک بهطور غیرمنتظره افزایش مییابد.
- تحلیل سریهای زمانی این الگو را شناسایی کرده و به مدل کمک میکند تا پیشبینیهای دقیقتری ارائه دهد.
5. استفاده از توزیعهای بیزی برای بهروزرسانی پیشبینیها
روشهای بیزی یکی از ابزارهای مهم آماری برای مدیریت عدم قطعیت هستند. این روشها با ترکیب دادههای قبلی و جدید، پیشبینیها را بهروزرسانی میکنند.
مثال:
در پیشبینی احتمال وقوع یک بیماری:
- احتمال اولیه: 10 درصد
- نتیجه آزمایش مثبت این احتمال را به 70 درصد افزایش میدهد.
این بهروزرسانی به پزشکان کمک میکند تا تصمیمهای دقیقتری بگیرند.
6. شناسایی دادههای پرت برای کاهش عدم قطعیت
دادههای پرت میتوانند باعث افزایش عدم قطعیت و کاهش دقت مدل شوند. ابزارهای آماری مانند چارکها و تحلیل واریانس به شناسایی این دادهها کمک میکنند.
مثال:
در تحلیل تراکنشهای بانکی:
- میانگین مبلغ تراکنشها: 1 میلیون تومان
- یک تراکنش با مبلغ 50 میلیون تومان شناسایی شده که بهعنوان داده پرت علامتگذاری میشود.
7. ارزیابی عملکرد مدل با آزمونهای آماری
آزمونهای آماری میتوانند برای ارزیابی دقت و میزان خطای مدلهای یادگیری ماشین استفاده شوند. این آزمونها به مدلها کمک میکنند تا عدم قطعیت در پیشبینیها را کاهش دهند.
مثال:
در پیشبینی تقاضای محصولات:
- مدل اول دقت 80 درصدی دارد، اما خطای آن در دادههای جدید بالا است.
- آزمون فرضیه نشان میدهد که مدل دوم با دقت 85 درصد و خطای کمتر، برای استفاده مناسبتر است.
8. ترکیب خروجیهای آماری و یادگیری ماشین
ترکیب خروجیهای آماری با مدلهای یادگیری ماشین میتواند به مدیریت بهتر عدم قطعیت کمک کند. این ترکیب باعث ارائه پیشبینیهای دقیقتر و قابل اعتمادتر میشود.
مثال:
در پیشبینی مصرف انرژی:
- تحلیل آماری نشان میدهد که میانگین مصرف انرژی در روزهای تعطیل 20 درصد کمتر از روزهای کاری است.
- مدل یادگیری ماشین این اطلاعات را برای پیشبینی دقیقتر مصرف انرژی در روزهای آینده استفاده میکند.
نتیجهگیری
ترکیب آمار و یادگیری ماشین، یک رویکرد جامع و قدرتمند برای بهبود پیشبینیها ارائه میدهد. آمار با تحلیل دادهها، شناسایی الگوها و مدیریت ناهنجاریها، پایهای قوی برای مدلسازی فراهم میکند، در حالی که یادگیری ماشین با قدرت پردازش دادههای بزرگ و شناسایی روابط پیچیده، دقت پیشبینیها را افزایش میدهد. این ترکیب در مسائل دادهمحور، از پیشبینی تقاضا تا شناسایی تقلب، نتایجی قابلتوجه داشته و نشان میدهد که چگونه هوش مصنوعی در آمار میتواند سیستمهای هوشمندتر و دقیقتری ارائه دهد.



